Demystifying Multi-Modal AI for Fashion Search & Beyond

Table of Contents
- Overview
- What is Multi-Modal AI?
- Multi-Modal Embeddings Explained
- Use Cases
- Why This Matters for Fashion Businesses
- Key Takeaways
Overview
In the past year, the fashion industry has been experiencing an unprecedented AI boom. A diverse ecosystem of innovative startups has emerged with a focus on both consumer and business use cases: digital closets, resale platforms, outfit recommendations, and AI-powered stylists to name a few. Underpinning all of these businesses is a transformative technology: "multi-modal AI." As major brands and retailers increasingly adopt these technologies, it's crucial to understand what this means for the future of fashion retail.
What is Multi-Modal AI?
For the fashion-forward folks reading this post, you may recognize a similarity between the words "moda" and "modal." The former being the Italian term for fashion ("mode" in French). Interestingly, both "modal", "moda", and "mode" share the same Latin root "modus", which means "a particular state of being."
In the context of AI systems though, a "modality" is simply a method of communicating information or data. So a "multi-modal" system is one that can work with multiple types of information and translate between them. The most relevant "modalities" for fashion being images and text, so we'll explore a variety of use cases that bridge the gap—approaches that can takein images and return text, take in text and return images, or use both modalities in tandem to return a result.
Multi-Modal Embeddings Explained
You may have heard the term "embeddings" or "vectors" being mentioned by major tech companies like OpenAI, Google, and Meta, but what are they? Embeddings are essentially lists of numbers that correspond to "concepts". This might sound abstract, but back in 2013, Google released Word2Vec, which took words and created associated "vectors" that allowed us to measure the "semantic" (conceptual) similarity between any two words.
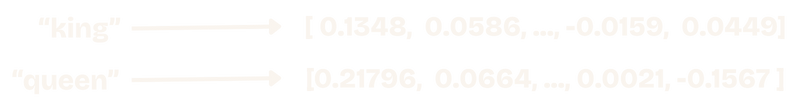
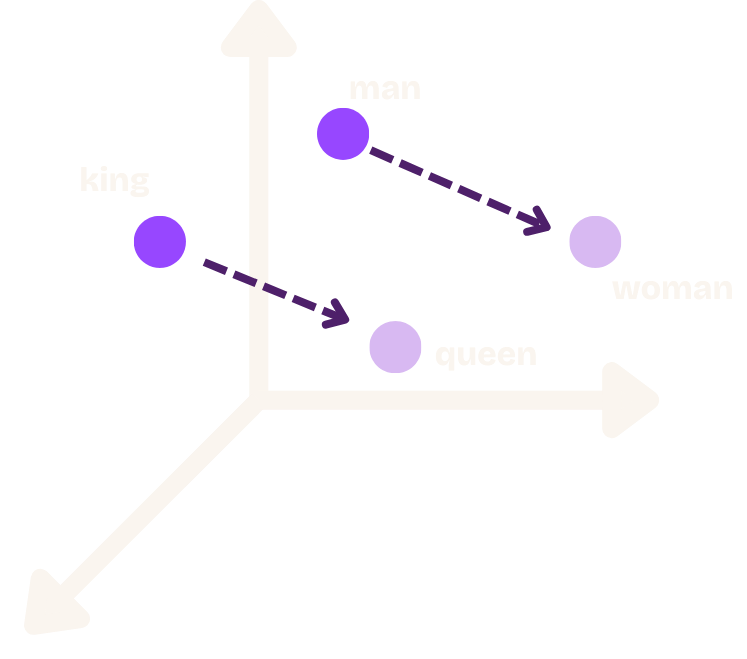
This is very useful, because we can take these standard representations and compare their "distances" (most often "cosine distance") to see how closely related different concepts are. This creates a powerful way of grouping objects by "similar meaning". The following diagram shows a representation of "man", "king", "woman", and "queen" in a 3D vector space, highlighting the "directional" nature of the relationships.
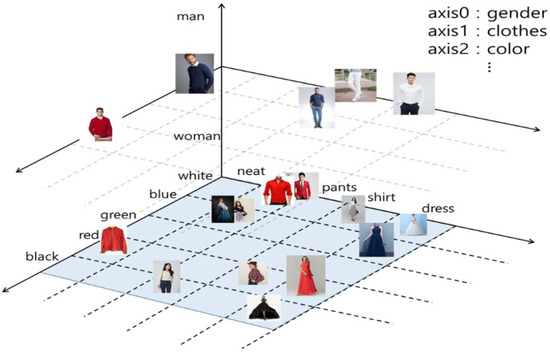
But how does this apply to fashion? Well, similar to Word2Vec, there are multi-modal embedding models that are trained on massive datasets of text/image pairs, producing models that can relate the semantic similarity between an image and a piece of text. For example, if I give an image of a red shirt and the literal text "red shirt" to the model, their embeddings should be very close together in this numerical space!
Use Cases
Vector Search for Fashion
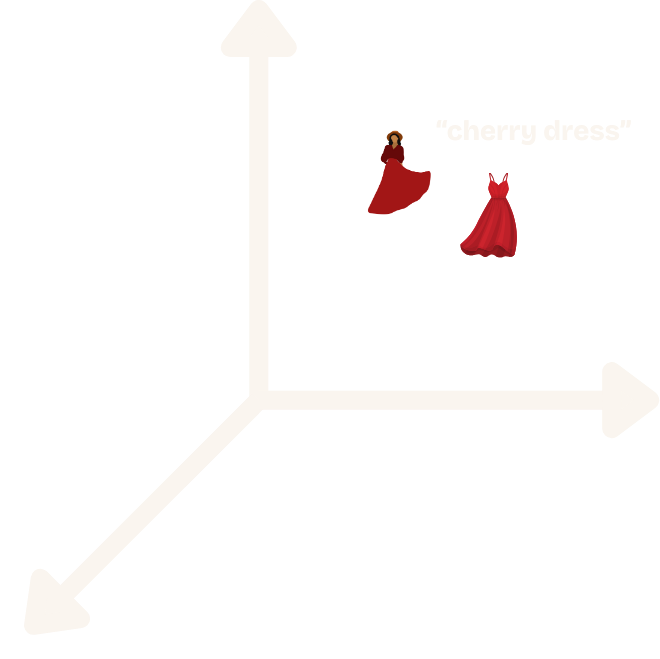
Perhaps the most immediately useful application of multi-modal embeddings is enhancing search capabilities. In traditional search systems, we need to ensure every item has detailed tagging and rich descriptions. For example, if a user searches for "cherry dress", we might miss relevant items if we don't have a "cherry" tag in our database or mentioned in the product description. But with multi-modal embeddings, our user's query "cherry dress" can be vectorized and we can retrieve semantically similar products via the distance measurement on the product image embeddings themselves. This is great because images of cherry-red dresses in the inventory will be similar, even if the word "cherry" isn’t present in the product description.
While this approach is powerful on its own, there are cases where we may want to include specific attributes like "designer" or "clothing type" in our search. This leads to a pattern known as "hybrid search" that combines both vector similarities and traditional keyword matching for the best results.
👉 Using our Multi-Modal Embeddings API, you can generate embeddings for your inventory and use them to power search. We can help you build a custom search solution or integrate with your existing search engine. Book a call or email us at info@wearnext.ai to discuss your use case!
Taxonomy and Classification
Another valuable multi-modal use case is taking an image and extracting structured information from it using a Vision Language Model (VLM). These models are trained to generate text descriptions from image inputs (utilizing some of the concepts used in embedding models). This technology helps us automatically apply accurate tags, taxonomies, and classification labels to new items with tremendous flexibility.

👉 With our Enrichment API, you can bring your own taxonomy or use our comprehensive standard taxonomy to automatically enrich tags, categories, descriptions, and metadata to your inventory. Book a call or email us at info@wearnext.ai to learn more!
Assortment Curation
Retailers and marketplace services frequently offer curated selections of inventory based on themes, occasions, and vibes. Traditionally, this required inventory to be explicitly tagged and used hardcoded logic to create these collections.
Multi-modal embeddings make this process largely automatic. Let's say we want to generate collections for Valentine's Day, Halloween, and Christmas. We can do this by embedding descriptions of these themes and retrieving the relevant inventory using the same approach we use for search.

👉 With our Trends Data API, you can generate collections for your inventory based on themes & occasions scraped from social media, the runway, or any other source. Book a call or email us at info@wearnext.ai to learn more!
Auto Styling / Complete the Look
One of the most exciting applications in the fashion space is automatically putting together cohesive outfits from multiple items. We can approach this in several ways, but a particularly effective method combines text output from a VLM with embeddings-based retrieval.
For example, if we have a pair of bell-bottom jeans and want to suggest items that complete the outfit, we can use an AI model to generate text descriptions of suitable complementary pieces ("bohemian blouse", "platform sandals", etc.) and then retrieve the most visually and conceptually similar clothing items from our inventory.

👉 Using our Complete the Look API, you can generate embeddings for your inventory and use them to provide recommendations to complete outfit looks or suggest coordinated multi-item bundles. Book a call or email us at info@wearnext.ai to learn more!
Key Takeaways
- Multi-modal AI combines different types of data (text, images, user behavior) to create powerful fashion technology applications
- Fashion-specific embeddings can be used to enable semantic search, and outfit recommendations, and complete the look
- Utilizing VLMs allows us to augment inventory with useful metadata in the form of custom taxonomy and enriched tags
- Multi-modal AI technology is accessible through specialized APIs without needing in-house AI expertise
- Retailers implementing these technologies can expect to see measurable improvements in conversion, AOV, and operational efficiency
- Early adopters of this technology will gain significant competitive advantages in the rapidly evolving fashion e-commerce landscape
At Wearnext, our specialized fashion AI solutions make these capabilities accessible without requiring in-house AI expertise. Whether you're looking to enhance search functionality, automate product categorization, or create outfit recommendations, our APIs integrate seamlessly with your existing platform.
📣 Ready to bring the power of multi-modal AI to your fashion business? Contact us at info@wearnext.ai or Book a call to discuss which solutions might be the right fit for your specific needs.